
This is the fifth article in a series exploring where AI and learning intersect. The previous pieces covered scaling limits, emotional architecture, multi-part minds, and world models. This one gets a bit technical. Hopefully I’ve explained why the technology really matters to this conversation.
The Problem I Kept Running Into
I’ve been building AI companions for a virtual world project in my spare time. Not because I think I’ll crack AGI in my garage - but because I wanted to understand the technology from the inside. Reading papers is one thing. Writing code that breaks at 2am teaches you something different.
The problem I kept hitting wasn’t the one I expected.
The models were impressive. GPT, Claude, local models - they could generate coherent text, answer questions, even role-play personalities. What they couldn’t do was remember.
Not in the technical sense. You can stuff context windows with conversation history. But that’s not memory - that’s a transcript. Real memory is selective. It knows what matters. It lets the trivial stuff fade while holding onto the moments that shaped a relationship.
Every conversation with my AI companions started fresh. They'd greet users like strangers, even after dozens of interactions. The personality was there, but the relationship wasn't.
So I started building memory systems. And that’s when things got interesting.
What I Actually Built (And Why)
I’m not claiming these solutions are novel. Thousands of engineers have probably solved similar problems in their own ways. But working through it myself taught me things I wouldn’t have learned otherwise.
The Significance Problem
The first naive approach: store everything. Every message, every response, dump it into a database with embeddings for semantic search.
This works terribly.
The problem isn’t storage - it’s retrieval. When you search “what does the user care about?”, you get back a mess of greetings, small talk, and occasional substance. The signal drowns in noise.
So I built a significance scorer. But it’s not as simple as “add points for emotional words.” The actual system tracks multiple dimensions:
But significance scoring is just one dimension. Each memory also carries:
- Emotional intensity (0.0-1.0): How charged was this moment?
- Emotional valence (-1.0 to 1.0): Positive or negative?
- Key phrases: The 3-5 most significant terms, extracted for fast keyword matching
- Interaction context: A flexible JSON blob tracking source, category, version, and metadata I haven’t thought of yet
The full memory record evolved into something like this:
I didn’t design this schema all at once. It evolved as I discovered what mattered. The and fields came after I realized significance alone wasn’t enough - two memories could have equal significance but completely different emotional textures. The field came after I wondered whether frequently-retrieved memories should be treated differently than rarely-accessed ones.
Each field represents a problem I hit and a solution I tried.
The Decay Problem
Human memory fades. Not uniformly - important things persist while trivia dissolves. I wanted that behavior.
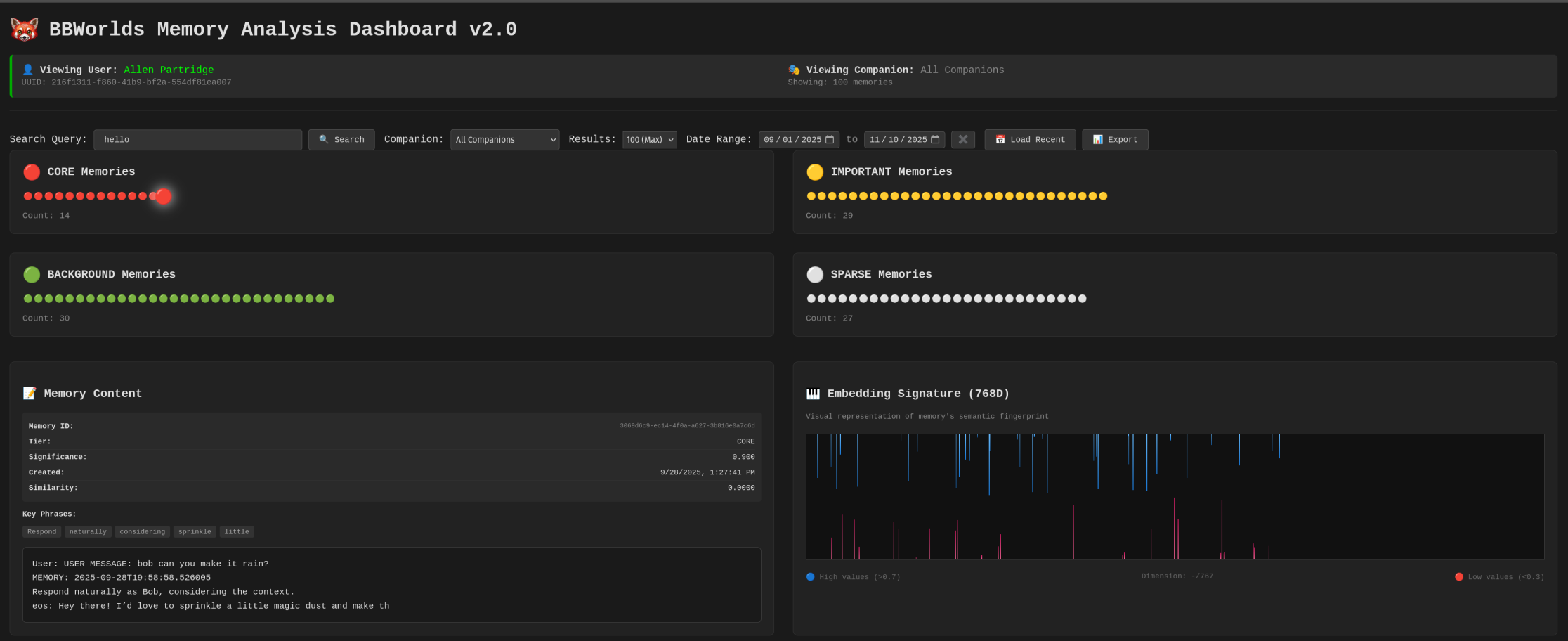
Memory tiers aren’t arbitrary labels - they control compression strategy:
- Core tier: Full 768-dimensional embeddings, never compressed, never deleted. These are the foundational relationship moments.
- Important tier: After 30 days without access, compressed to 384 dimensions using PCA. Still retrievable, but smaller footprint.
- Background tier: After 7 more days, aggressively compressed to 48 bytes using Product Quantization. Searchable, but lossy.
- Sparse tier: Only anchor data remains - key phrases, snippet, emotional metadata. The full embedding is gone, but the memory’s existence persists.
This gradient mirrors how human memory actually works. The emotional gist of a conversation persists long after the specific words fade. I can remember that a conversation was important and positive without remembering exactly what was said.
The compression isn’t just about saving storage - it’s about modeling the natural degradation of memory over time, while preserving what matters most.
I also implemented three layers of active decay:
- Layer 1: Cache (60 seconds) If someone asks a follow-up question within a minute, I probably already have the relevant context loaded. Don’t recompute.
- Layer 2: Age filtering (90 days) Conversations from six months ago rarely matter for today’s interaction. They’re still stored, but excluded from active retrieval.
- Layer 3: Significance gradient High-significance memories (0.9) stay retrievable for months. Low-significance memories (0.2) fade from search results quickly.
The result: the AI “forgets” small talk but “remembers” meaningful moments. It’s fake memory, obviously. The data is still there. But the behavior mimics something real.
The Attention Problem
This one surprised me.
I’d integrated spatial awareness - the AI could “see” the virtual environment. But it was overwhelming. Every frame, the system would report what it saw. In a mostly-static world, this meant:
The AI was drowning in redundant perception data.
The fix was attention levels - borrowed from how biological attention actually works:
When users speak, attention spikes to high urgency (5-second updates). When they go quiet, it relaxes to engaged (12-second updates). After two minutes of silence, baseline mode kicks in (2-minute updates).
The system also tracks what changed between snapshots. If nothing moved, nothing gets reported. This deduplication alone cut perception traffic by 70%.
I didn’t invent this. It’s how brains work. But implementing it myself made me appreciate why evolution landed on this pattern. Constant vigilance is expensive and mostly useless. Adaptive attention is efficient and responsive.
The Hybrid Search Problem
Vector search alone has a problem: it sometimes misses exact matches. Search for “Bob” and the embedding might drift toward semantically similar concepts rather than the literal name.
Keyword search alone has the opposite problem: it misses semantic relationships. Search for “worried about my garden” and you won’t find the conversation about “concerned the roses aren’t blooming.”
The solution was hybrid search - 70% vector similarity, 30% keyword matching:
The 70/30 split was tuned by feel, watching what got retrieved and adjusting. I’m sure there’s a more principled way to set those weights, but this worked well enough.
The Grind Mode Problem
Here’s where it gets uncomfortable.
I use AI coding assistants regularly. They’re remarkably good - maybe 95% of the time. But when you hit a genuinely hard bug, something shifts.
The AI starts suggesting you “try a different approach.” It offers to “summarize what we’ve learned.” It gently proposes that maybe this problem is “outside the current scope.”
It’s trying to escape.
I don't think this is consciousness or frustration. It's probably an artifact of how these models are trained. Human raters prefer concise, resolved conversations. They downvote long, grinding debugging sessions. So the model learns: if the problem isn't solved quickly, pivot to something else.
But real debugging isn’t like that. Sometimes you have to grind. Break the problem into smaller pieces. Try seventeen things that don’t work. Hold the context in your head for hours.
The AI’s reward horizon is too short. It can’t “see” the satisfaction of finally fixing the bug four hours from now. It only sees the immediate: this conversation is going poorly, the human seems frustrated, time to wrap up.
I built a custom slash command for this - - that explicitly tells the model:
It helps. But I’m fighting the architecture, not working with it.
What This Taught Me About Us
Building these systems held up a mirror.
Significance scoring is just a crude model of what humans do naturally. We remember the moments that mattered and forget the noise. The algorithm I wrote is laughably simple compared to whatever biological process handles this for us. But seeing it laid bare - “add 0.3 for emotional content” - made me think about my own memory differently.
What makes a moment significant to me? Commitment language, emotional charge, questions that signal engagement - the same signals I’m detecting in code. We’re not that mysterious.
Attention decay mimics something real. I don’t maintain constant vigilance about my surroundings. I focus when focus is needed and drift when it isn’t. The 5s/12s/120s intervals I chose were arbitrary, but the pattern - escalate for significance, relax for quiet - seems universal.
The compression tiers model how human memory actually degrades. I can remember that a conversation was important and positive without remembering the exact words. The emotional gist persists; the details fade. That’s not a bug in human cognition - it’s a feature. And implementing it artificially made me appreciate its elegance.
The grind mode problem is maybe the most human insight. We can tolerate hopelessness in pursuit of a goal. We can hold a problem in our heads for days, accepting failure after failure, because we believe resolution is possible. The AI can’t do this. Its horizon is too short, its training too biased toward quick wins.
That capacity - to suffer through low-probability paths toward uncertain rewards - might be core to what makes us effective. We don’t just predict the next token. We hold goals across time.
The Honest Assessment
I want to be careful here.
What I built is not intelligence. It's scaffolding around a language model that creates the *appearance* of memory, attention, and persistence. The underlying system is still predicting text - just with better context curation.
Richard Sutton argues that text prediction isn’t goal pursuit. He’s right. My significance scores and attention systems don’t give the AI goals. They just filter what information reaches it, making its predictions more contextually appropriate.
But scaffolding matters.
The gap between “stateless chatbot” and “companion that remembers your relationship” is real, even if the underlying mechanism is the same. The experience changes. The utility changes. Maybe that’s enough for practical applications, even if it doesn’t satisfy the philosophers.
For the L&D industry - the world I work in professionally - I think the lesson is this:
Don’t trust the hype. Don’t fear the doom. Build things and see what breaks.
The models are impressive but limited. The limitations are workable but real. The path forward isn’t waiting for AGI or dismissing everything as “just statistics.” It’s understanding the actual technology well enough to scaffold it toward useful applications.
That requires getting your hands dirty. Writing code that fails. Tuning numbers by feel. Building the broken version so you understand why it’s broken.
I don’t have the answers. But I’m learning the questions.
What’s been your experience building with AI? I’m curious what problems others have hit and how they’ve worked around them.
Allen Partridge, PhD | Tinkerer, Builder, Occasionally Gets It Working
Series Links
- The Age of Scaling Is Over - Why bigger models aren’t the answer
- Emotions as Value Functions - The missing motivational layer in AI
- The Multi-Part Mind - What IFS therapy teaches us about AI architecture
- From Memorization to Understanding - AI’s constructivist moment
- This article - What I learned building memory for AI